|
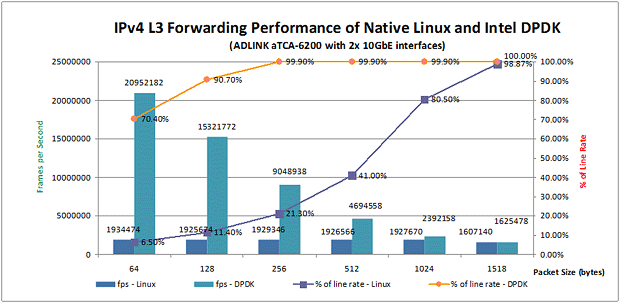
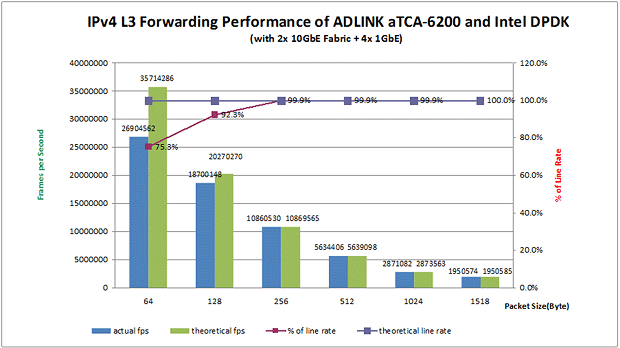
���ԭ�� Linux��Native Linux��������Intel® DPDK���g���܉�������IP�D���ܵ���Ҫԭ������Intel® DPDK������������������Ҫ������
݆ԃģʽȡ���Д�
ͨ�����������M��ĕr��Native Linux���ľW�j�ӿڿ�������NIC��Network Interface Controller�����յ��Д࣬Ȼ���{��ܛ�Д࣬�����õ��Д��M���������ГQ��������ϵ�y�{�ã���read������write������
���֮�£�Intel® DPDK�����˃�����݆ԃģʽ�ӣ�PMD��Poll Mode Driver������Ĭ�J����̫�W�ӳ��Ķ����Բ���ؽ��Ք�����������ܛ���Д࣬�������ГQ�͆���ϵ�y�{�ã��Ķ����Ĺ�ʡ��Ҫ��CPU�YԴ�����ҽ��������t��
HugePageȡ�����y�
���Native Linux��4kB 퓣����ø����퓳ߴ���ζ�����Թ�ʡ퓵IJ�ԃ�r�g�����p���D�g���Ҿ��棨TLB��Translation Lookaside Buffer���Gʧ�Ŀ��ܡ�
Intel® DPDK�����Ñ����g��User-space�������\�Еr�����Լ��ăȴ���g�з���HugePage���惦�����_�^���h�κ��������P���_�^���@Щ���_�^�����������ó�����ƣ�������Linux�Ⱥˡ�����Ƥ�������Ĝyԇ�У���Ӌ1024@2MB��HugePage�����������\��IP�D�l���á�
�㿽ؐ���_�^
�ڂ��y�Ĕ�����̎���^���У�ԭ�� Linux��Native Linux�������Ĉ��^��Ȼ�����Socket ID���������Ƶ��Ñ����g��User Space�����_�^��һ���Ñ����g��User Space�����ó�������˔�����̎����һ��write����ϵ�y�{�Ì������Ѳ��є��������Ⱥˣ�ؓ؟���������Ñ����g��User Space����ؐ���Ⱥ˾��_�^�����b���Ĉ��^�����������P�������˿ڌ������l��ȥ���@Ȼ��ԭ�� Linux��Native Linux���ڃȺ˾��_�^���Ñ����g��User Space�����_�^֮�g�M�п�ؐ�����������˺ܶ�ĕr�g���YԴ��
���֮�£�Intel® DPDK���Լ������ăȴ�^����Ք��������@���^��λ���Ñ����g��User Space�����_�^��֮���������Ҏ�t���@Щ���������ÿһ��Flow�С���̎�������֮������ͬ���Ñ����g��User Space�����_�^��ʹ�����_�Ĉ��^�M�а����b�����ͨ�^���P�������˿ڰl���@Щ������
Run-to-Completion(RTC���\����)��Core Affinity
�ڈ��Б���֮ǰ��Intel® DPDK���M�г�ʼ�����������еĵͼ��YԴ����ȴ���g��PCI�O�䣬���r���������_���@Щ�YԴ���������҃H������Щ����Intel® DPDK�đ��á���ʼ�����֮��ÿһ���ˣ��̣���BIOS�O���І�����Intel®�����̼��g�r���������Á�ؓ؟ÿһ�����І�Ԫ�����������H���õ������\����ͬ�Ļ�ͬ�Ĺ���ؓ�d��
���⣬Intel® DPDK߀�ṩ��һ�N�������������O��ÿ�����І�Ԫ�\����ÿһ�������ϣ��ԾS�ָ����Core Affinity���Ķ����⾏��Gʧ���ڴ˰�Ƥ�������Ĝyԇ�У�aTCA-6200̎������Ƭ�������˿ڸ���Affinity�������ڃɂ���ͬ��CPU�����ϡ�
�o�i���к;���У��
Intel® DPDK�ṩ�Ď��API���������ɟo�i���Է�ֹ�ྀ�̑��ó������i�F��İl�������ھ��_�^���h�κ����������Y����Intel® DPDKҲ�M���˃����������˾���У�ʣ����_�������У�Cache-Line����Ч�����ͬ�r����Ȝp�پ����У�Cache-Line���ě_ͻ��
|