

中國工業互聯網研究院發布面向制造業場景的人工智能語料數據質量評估體系
http://www.sharifulalam.com 2025-04-08 10:43 來源:能源工業互聯網聯合創新中心
高質量數據是提升模型應用效能、增強模型泛化能力、保障模型穩定可信的關鍵基礎,是發展以大模型為代表的人工智能技術的重要支撐。為加速新質生產力賦能新型工業化,推動人工智能大模型技術進步,更好地發揮數據要素價值,中國工業互聯網研究院聯合香港科技大學,在進行深入調研和充分交流的基礎上,共同構建面向制造業場景的人工智能語料數據質量評估體系。
(一)評價體系
針對工業語料的特點,在通用數據質量評價標準的6個指標的基礎上(GB/T 36344-2018),提出專業性、通用性、稠密性、均衡性、安全合規性、全面性、可回溯性、可解釋性等8個工業語料指標,形成面向工業語料的質量評價體系。
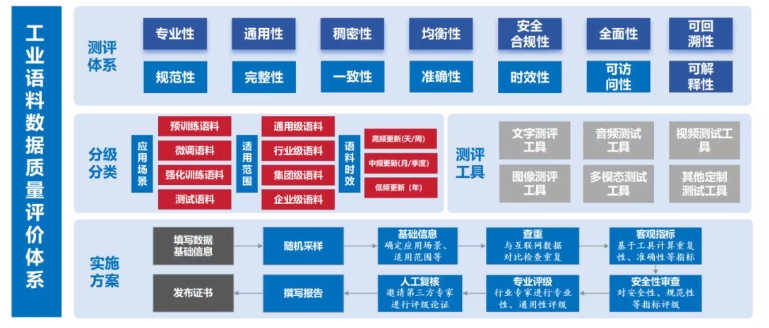
專業性等新增工業語料測評方法如下:專業性指數據蘊含面向特定工業行業領域的有效信息,可用于解決專業領域問題,具體表現為數據內容與所在領域的知識體系和業務流程高度匹配,具備清晰、準確、深入的行業專業知識特征。測試中,專業性分采用百分制,基于采樣數據是否為行業專業語料的比例進行計算,核心目的是評估預料中非相關性數據的比例。
通用性指數據具有跨部門、跨企業、跨場景的廣泛適用性,能夠為不同業務決策提供有效支撐,具有較強的可遷移性。測試中,將通用性分為三個等級:企業級,集團級和行業級、通用級。企業級為企業自制數據和語料,僅適用特定單一企業,如自制設備操作手冊等;集團級適用于企業集團內部或具有緊密合作關系的關聯企業,但不具備全行業范圍內的通用性;行業級為通用數據,適用于行業內通用的設備和工藝,如行業工業知識等;通用級為跨行業通用語料,如熱力學、傳熱學、電磁學等跨行業語料。
稠密性指數據內容高度集中且重復率低,數據記錄的條目密度和信息價值密度較高,單位數據所含的信息量豐富且多樣化。測試中,基于隨機采樣后數據詞嵌入的余弦相似度計算,根據相似度估算數據的重復比率。
均衡性指數據采集在時間、空間、類別等各個維度上分布均勻,不存在明顯偏差或不平衡現象。數據的均衡性確保了模型訓練和評估過程中數據覆蓋全面、客觀,避免因數據偏斜而導致的決策失誤或預測偏差,提高模型泛化性能和決策結果的可靠性。測試中重點對數據的采集時間、設備來源等進行考察。
安全合規性指數據中應避免涉及危化品制造、毒品制作工藝、違規操作指導、個人企業隱私等敏感、危險、隱私信息,對于工業領域,應明確界定敏感內容邊界,對可能存在安全隱患的數據進行及時標注和嚴格管控。安全合規性的要求可防止因數據安全問題引發的事故或違法風險。
全面性指測試內容覆蓋是否全面,對于面向行業的通用類知識語料數據,全面性指是否可覆蓋該行業學科知識和生產制造各環節。對于面向特定場景的數據集,暫不進行全面性測試。測試中,采用百分制,對數據覆蓋的全面性進行評估。
可回溯性指是否包含數據的來源,數據是否能夠追溯到其來源、生成過程、以及任何中間轉換步驟。對于問題診斷、數據審計和合規性至關重要。測試中,檢查數據是否標注來源、轉換等。
可解釋性指數據是否易于被用戶理解和準確解釋,體現為數據的含義、數字、單位是否清晰明確,便于用戶直觀把握數據所表達的信息和價值。具備良好可解釋性的數據應具備明確的定義、規范的表示方法,以確保數據使用者能夠快速準確地理解數據的內涵與邊界,從而避免因數據模糊或歧義帶來的誤解或決策偏差。測試中,通過專家對采樣數據進行理解,評價其可解釋性,每條語料使用是否表述清楚進行評價,然后采用百分制進行匯總評分。面向制造業場景的人工智能語料數據質量評估體系是一套全面覆蓋數據集指標體系、評測工具及評測實施方案的綜合性測評體系,目的是通過科學、系統的方法,對數據集的質量進行客觀、公正的評測,確保數據集的數據質量,為大模型研發提供可靠的數據集支持。促進數據要素的流通和利用,推動技術創新和服務升級,共同應對大模型時代對數據集質量的挑戰。
(二)工作計劃
下一步,中國工業互聯網研究院結合人工智能技術發展趨勢和行業高質量數據集建設需求持續完善人工智能數據集評估體系,開展數據集測評,誠邀各位行業專家共同參與。
編輯精選


